Uczenie maszynowe (ML – Machine Learning), reklamowane jako jedna z bardziej pożądanych kompetencji w obecnych czasach, staje się wszechobecne – od autonomicznych pojazdów poprzez obsługę klienta aż po autonomiczne bazy danych. Praktycznie nie ma dziedziny czy branży, generującej codziennie ogromne ilości danych, w której uczenie maszynowe nie znajdywałoby zastosowania. Z kolei dostawcy platform ML wykładają ogromne sumy na badania i rozwój w zakresie nowych narzędzi i frameworków w szybkim tempie udostępniając nowe wersje i nowe funkcjonalności.
Wszystko to sprawia, że przeciętny inżynier oprogramowania, deweloper / programista, freelancer znajduje się pod pewną presją, aby kompetencje związane z uczeniem maszynowym nabyć i rozwijać. Podążając za tym trendem rośnie liczba kursów i szkoleń, publikacji przybliżających metody, narzędzia i technologie, sama liczba kursów online na platformach MOOC podwoiła się z 2017 roku. Wiele instytucji obiecuje możliwość przekształcenia programistów w inżynierów uczenia maszynowego. Niestety ta obietnica, choć na fali popularności trafia na podatny grunt, jest bez pokrycia bez bliższego zapoznania się z wymaganiami, jakie stawia dziedzina uczenia maszynowego jej adeptom oraz predyspozycji jakie należy posiadać. Przekwalifikowanie się dewelopera w inżyniera uczenia maszynowego jest wyzwaniem, mają tego świadomość autorzy książek, jak np. ta poniżej.

Oto niektóre z wyzwań, które muszą pokonać programiści, aby opanować podstawy uczenia maszynowego.
Matematyka u podstaw
Przeciętny programista nie ma do czynienia z matematyką w codziennej pracy, jeśli już jest potrzeba to ma do dyspozycji gotowe biblioteki. Co więcej – stopień zaawansowania matematycznego u deweloperów jest bardzo różny ze względu na różne drogi edukacji, jakie mają za sobą. Bez wątpienia w dobrej sytuacji są tutaj osoby z wykształceniem inżynierskim (informatyka), matematycznym czy fizycznym, oraz statystycznym i ekonometrycznym. Taki też rodzaj wykształcenia podają najczęściej pracodawcy jako preferowany podczas rekrutacji na stanowiska związane z uczeniem maszynowym.
Aby opanować, zrozumieć i kompetentnie operować narzędziami uczenia maszynowego matematyka jest obowiązkowa. Algebra liniowa, statystyka i rachunek prawdopodobieństwa, czy też analiza matematyczna w przypadku zaawansowanych prac z modelami uczenia głębokiego stanowią kanon uczenia maszynowego. Jeśli jesteś programistą z poważnymi planami dołączenia do zespołu ML, to czas, aby odświeżyć matematykę ze studiów – to z pewnością godna inwestycja.
Potrzeba analizy danych
Kolejną po matematyce fundamentalną umiejętnością w dziedzinie uczenia maszynowego jest umiejętność analizy danych. Przy czym nie obejmuje ona tylko strony technicznej związanej z operowaniem dużymi zbiorami danych, ale również zdolność analitycznego myślenia, spojrzenia na zbiór danych pod różnymi aspektami i zadawania właściwych pytań. Nie każdy deweloper posiada naturalny talent do “hackowania” zbiorów danych a takie działania jak ładowanie, czyszczenie, próbkowanie, uzupełnianie brakujących danych w dużych zbiorach należą do kluczowych w procesie uczenia maszynowego.
Innym ważnym aspektem jest umiejętność wizualizacji, interpretacji wykresów i zastosowania różnych przydatnych technik jak np. tabele przestawne w Excel.
Język i framework
Python przeważa w zestawieniach jako preferowany język dziedziny uczenia maszynowego. Dostępność bibliotek i narzędzi open source sprawia, że jest to idealny wybór do opracowywania modeli ML i chociaż R jest preferowany przez statystyków, Python jest zalecany dla większości programistów stawiających pierwsze kroki w uczeniu maszynowym. Języki takie jak Julia zyskują na popularności, ale to Python ma najlepiej rozwinięty ekosystem.
Kolejnym aspektem pracy nad modelem uczenia maszynowego zestaw bibliotek. Obecnie programiści mają szeroki wybór spośród różnych frameworków i bibliotek, będących głównie modułami Pythona, takie jak NumPy, Pandas, SciPy, Scikit-Learn, a następnie zestawy narzędzi open source, takie jak Spark MLib, Caffe2, Keras, Microsoft Cognitive Toolkit, TensorFlow i PyTorch. Programista może czuć się na początku trochę zdezorientowany.
W przypadku programistów Pythona najlepiej zacząć od Scikit-Learn, aby zbudować i zastosować podstawowe modele uczenia maszynowego, zanim zacznie się odkrywać zaawansowane zestawy narzędzi, takie jak TensorFlow, Caffe2 i Keras. Połączenie Pythona i Scikit-Learn jest wystarczające do rozpoczęcia przygody z ML.
Wiele podejść do rozwiązania tego samego problemu
Po nauczeniu się korzystania z narzędzi i modułów programista zmierzy się z zadaniem wyboru konkretnego algorytmu właściwego do rozwiązania postawionego problemu. Uczenie maszynowe oferuje zestaw gotowych metod i algorytmów, które najlepiej nadają się do rozwiązania konkretnej klasy problemu, ale nie ma jednej gotowej odpowiedzi na pytanie KTÓRĄ metodę najlepiej zastosować w konkretnym przypadku. Umiejętność zadawania właściwych pytań i myślenia abstrakcyjnego jest tutaj kluczowa. Typowym podejściem jest też stosowanie wielu metod i algorytmów i wybór właściwego na podstawie osiągniętej precyzji i dokładności modelu.
Brak narzędzi do programowania i debugowania
Niestety istniejące narzędzia programistyczne nie są gotowe do wykorzystania w dziedzinie ML. Deweloperzy przełączają się na zupełnie inny zestaw narzędzi do opracowywania modeli. Chociaż narzędzia takie jak Jupyter Notebooks są solidne i dojrzałe, zasadniczo różnią się od tradycyjnych narzędzi programistycznych. Debugowanie modelu ML jest niezwykle trudne w porównaniu z tradycyjnym procesem programistycznym. Dostawcy IDE, tacy jak Microsoft, pracują nad zapewnieniem bezproblemowej obsługi narzędzi dla inżynierów uczenia maszynowego, ale opłaca się opanować Jupyter Notebooks aby pracować w sposób interaktywny nad aplikacjami w Pythonie.
Zalew oferty edukacyjnej
W ostatnich latach nastąpiła eksplozja kursów do samodzielnego przejścia oraz MOOC. Biorąc pod uwagę szeroką domenę uczenia maszynowego, żaden kurs tak naprawdę nie dostarcza pełnego zakresu wiedzy. Z kolei narzędzia i biblioteki szybko ewoluują, pojawiają się nowe. Media społecznościowe i blogosfera są pełne artykułów, tutoriali i przewodników związanych z ML ale należy uważać na treści sprzeczne a nawet wprowadzające w błąd. Warto korzystać ze źródeł zweryfikowanych, cieszących się zaufaniem.
Typowe wymagania na stanowiska inżyniera ML
Brak jest standardu w zakresie wymagań na stanowiska związane z uczeniem maszynowym (engineer / scientist) ale oczywiście można pokusić się o zestawienie typowych wymagań:
- 3 lata doświadczenia w stosowaniu rozwiązań do uczenia maszynowego w rozwiązywaniu problemów biznesowych.
- doświadczenie praktyczne z nadzorowanymi i nienadzorowanymi algorytmami uczenia maszynowego do regresji, klasyfikacji i grupowania
- doświadczenie z wykorzystaniem danych strukturalnych i niestrukturalnych
- doświadczenie inżynierskie w Javie / C++ / Python
- zdolność rozwiązywania problemów i umiejętności analityczne
- znajomość konkretnej domeny jak wyszukiwanie informacji, NLP, rozumienie mowy, systemy rekomendacji itp.
- doświadczenie w pracy z rozwiązaniami NoSQL, takimi jak Cassandra, Redis, MongoDB
- doświadczenie w analizie dużych zbiorów danych, przy użyciu Hadoop, Spark lub technologii pokrewnych
- znajomość statystyki i analizą szeregów czasowych
- mgr lub dr w zakresie informatyki lub w pokrewnej dziedzinie
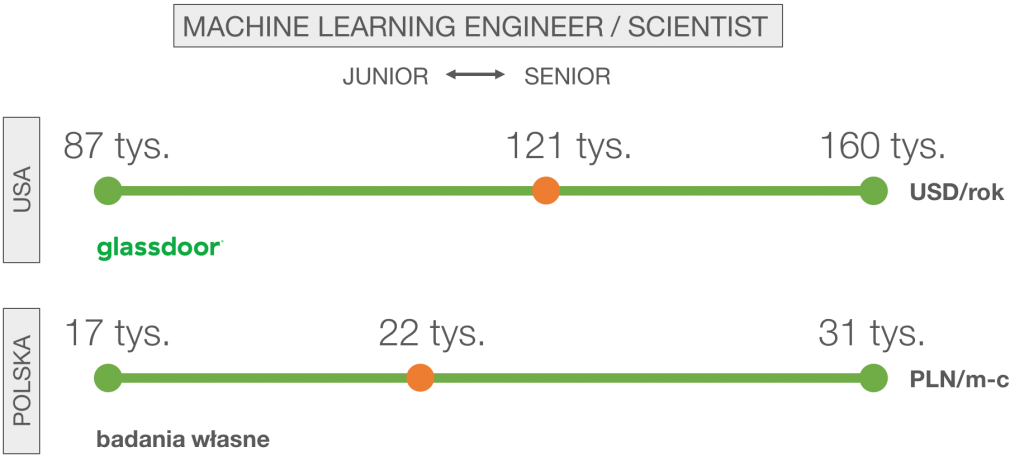
Przedstawione poniżej widełki wynagrodzeń zostały przygotowane na podstawie rozmów z pracodawcami i ofert kierowanych na rynek, zarówno dla UoP jak i B2B. W zatrudnieniu ekspertów uczenia maszynowego przewodzą przedsiębiorstwa międzynarodowe tworzące w Polsce centra kompetencji oraz firmy polskie oferujące takie usługi klientom zagranicznym.