
Fundamentalne pytanie. Można znaleźć wiele artykułów o benefitach chmury. Dlaczego warto? Bezpieczeństwo, audytowalność, wysoka dostępność usług, elastyczność, skalowalność, sporo łatwych w użyciu, zarządzanych usług. Często pojawia się też argument, że chmura jest efektywna kosztowo… ale jak jest naprawdę?
Na temat kosztów chmury można spotkać skrajne opinie, od wychwalających po krytyczne. Być może Ty również zaczynasz czytać ten artykuł z jakąś tezą. Zapewne skrajną:
– “Chmura jest tania! Widziałem use-case gdzie koszty zmniejszały się kilkukrotnie po migracji do chmury.”
albo –
“Chmura jest droga! Własne DC jest tańsze, a poza tym co własne to własne, a nie jakieś takie, dostarczone. Własną pizzerię też kupiłem, bo w końcu co własne to własne, na mieście jadać nie będę!”
A może nie masz jeszcze zdania? Czytając dalej, dowiesz się:
- kiedy chmura (z finansowego!) punktu widzenia ma sens,
- jak podejść do liczenia kosztów aplikacji w chmurze i jakie są dostępne narzędzia do liczenia oraz optymalizacji kosztów,
- poznasz też wyliczenie kosztów przykładowej aplikacji oraz metodologię wyceny, a także “niespodzianki”, na które można natrafić.
Niektóre odniesienia i wyliczenia opierają się na chmurze AWS, ale większa część opracowania jest uniwersalna. Amazon, Google czy Microsoft – wiele usług i problemów związanych z kosztami jest identyczna, niezależnie od dostawcy. Zatem kto ma rację?
Odpowiedź jest (nie taka) prosta: WSZYSCY
Chmura może być i tania, i droga. Wszystko zależy od tego, jak będziemy jej używać. To trochę jak z wydajnością aplikacji w naszych firmach. Jeżeli zrobimy coś na szybko, nieoptymalnie – będzie działać. Jednak koszt, w postaci nieoptymalnego działania lub chudszego portfela bo ostatecznie potrzeba więcej zasobów, może nas zaskoczyć. Wystarczy jednak poświęcić trochę czasu na optymalizację, aby było szybciej/taniej, czasem wielokrotnie. Tak samo jest z kosztami chmury – jeżeli zrobimy to bez planu, zapewne będzie drogo, ale jeżeli rzetelnie podejdziemy do tego tematu – opłaci się na pewno.
Może się okazać, że chmura – z uwagi na charakter naszego biznesu – po prostu nie jest opcją dla nas. Przykładowo, jeżeli mamy już działającą aplikację której głównym zadaniem jest wysyłać dane do klientów, którzy znajdują się tylko w Polsce – nie będziemy mieli specjalnych benefitów z wykorzystania chmurowego CDN (Content Delivery Network), a koszty wysyłania danych z chmury do Internetu mogą zjeść nasze zyski. Ale też nie można powiedzieć, że takie implementacje w chmurze nie mają sensu. Jest ich sporo, wymieniając największych – Netflix (z osobnym CDN) czy MLBAM (który także obsługuje HBO GO i NHL) w Amazone Web Services (AWS), albo Spotify w Google Cloud Platform (GCP).
Wreszcie, chmura nie musi być odpowiednia dla każdej aplikacji, którą mamy. Może być świetna do przetwarzań batchowych, hurtowni danych, data lake, IoT, uczenia maszynowego, serwowania danych naszym klientom. A może nie być tak świetna (kosztowo) dla baz danych DB2, aplikacji monolitycznych, radia internetowego z dużą ilością odbiorców w jednym kraju. Ale nadal może mieć sens przenieść część aplikacji do chmury, lub wykorzystywać ją do nowych rozwiązań, które dopiero tworzymy.
No dobrze, to od czego zależy, czy chmura w naszym przypadku będzie tania czy droga?
Wiedza
Nie ma innej drogi – chmurę, jej specyfikę trzeba rozumieć. Nie jest istotne, jaka to będzie chmura, ważne, aby wycenę zrobił ktoś, kto zrobił coś więcej, niż uruchomił instancję u jednego dostawcy. Musi rozumieć podstawowe usługi, jak działają, jak to się przekłada na koszty.
Jest to potrzebne po pierwsze po to, aby zaplanować architekturę naszej aplikacji optymalnie kosztowo, a po drugie, aby w wycenie nie pominąć jakiegoś zdawałoby się nieistotnego aspektu, który diametralnie zmienia wycenę. Przykładem może być przechowywanie danych – jeżeli wykorzystamy do tego wolumeny dyskowe – będzie OK. Ale może możemy użyć dedykowanego rozwiązania typu S3 w AWS czy Cloud Storage w GCP i będzie to kilkukrotnie tańsze.
Poza tym wszystkim, ważne jest także śledzenie rozwoju usług których używamy oraz nowych, które dostawca chmury dostarcza. Nowe funkcjonalności (ang. features) pozwalają czasem diametralnie zmniejszyć koszty które ponosimy, ale jeżeli się o tym nie dowiemy – dalej będziemy płacić “po staremu”.
Przykładowo, jeżeli w chmurze AWS mamy kilka VPC, z którymi mamy zestawione site-to-site VPNy (wykorzystując dwóch ISP – failover), to za każde podwójne połączenie z VPC zapłacimy ok $70/mc. Ale od jakiegoś czasu jest już AWS Transit Gateway, który w tym scenariuszu pozwala zredukować ilość tuneli. A może w ogóle nie potrzebujemy tuneli tylko możemy wykorzystać AWS SSM Session Manager? Tylko skąd będziemy o tym wiedzieć, jeżeli nie śledzimy rozwoju usług chmurowych?
Wiedza jest nam też potrzebna, do zrozumienia czegoś, czego nikt nie lubi, czyli
Koszty stałe
Chmura jest zawsze reklamowana jako model pay-as-you-go – płacisz tyko za to co używasz. Ma to sens i dla dostawcy, i dla nas. Dla dostawcy – rzecz oczywista, ale dlaczego dla nas? Założenie jest proste – to co robisz w chmurze, przynosi dochód. Więc jeżeli nasza chmura generuje więcej kosztów niż zakładaliśmy z uwagi na większy ruch klientów – to powinno to także przekładać się na większy dochód, a więc większy koszt chmury jest czymś normalnym. Kierowca Ubera też nie jest zaskoczony tym, że większa ilość klientów to częstsze wizyty na stacji benzynowej, bo dzięki tym klientom jego dochód rośnie.
Jakich kosztów stałych możemy się spodziewać?
Prawidłowa odpowiedź brzmi 0+
Dla standardowej konfiguracji, czyli 5+ kont AWS (PROD, DEV, IAM, AUDIT, OPS) oraz 1 VPC w każdym koncie PROD/DEV, koszty nie będą znaczące. Będą się sprowadzały do
- połączeń VPN – dwa pojedyńcze tunele do VPC na koncie PROD i DEV – $70/mc
- NAT gateway – 4 sztuki dla dwóch kont PROD & DEV i dwóch AZ w każdym koncie – $130/mc
Owszem, w/w usługi są w modelu pay-as-you-go, ale co z tego… wyjścia do Internetu czy do naszej sieci dla naszych zasobów w chmurze nie odetniemy w godzinach wieczornych/nocnych/weekendy (no, chyba że możemy).
Reszta kosztów jest zależna od ilości uruchomionych zasobów (transfer sieciowy, generowane logi) lub jest pomijalna (mała ilość alertów Cloudwatch, S3 na logi dla samej podstawowej infrastruktury).
Ale są i skrajności. Koszty stałe mogą być bliskie zeru, jeżeli nie mamy potrzeby kreowania VPC – np. nie mamy serwerów, aplikacje są serverlessowe, dane na S3 czy np. w DynamoDB.
Jednak dla zaawansowanej konfiguracji, którą wykorzystują największe firmy mające konkretne wymagania wewnętrzne lub regulacyjne, które budują w chmurze własną bramę do świata zewnętrznego, z serwerami proxy, reverse proxy, z klastrem Splunka, z serwerami realizującymi funkcje VPN, WAF, FW, DLP i inne chwytliwe 2-3 literowe skróty – taki koszt będzie wielo, wielo, WIELOkrotnie wyższy. Pracowałem przy implementacjach które kosztowały dziesiątki tysięcy dolarów miesięcznie za samą bramę na świat.
Case study
Szczegółowe omówienie metodyki wyceny na przykładzie aplikacji migrowanej z datacenter on-premises do chmury AWS dostępne jest w pełnej wersji artykułu (do pobrania), natomiast architektura aplikacji w chmurze i wyliczenia dostępne są tutaj.
Dokładność wyceny
Wycena w chmurze jest tak dokładna, jak dane, którymi dysponujemy oraz wiedza, jak ich użyć. Wiedza to coś, nad czym mamy kontrolę, ale z tymi danymi zazwyczaj nie jest tak różowo, jak moglibyśmy pomyśleć.
We wcześniejszym przykładzie podałem dość dokładne wymagania do wyceny. Procesor, pamięć, storage – to są proste rzeczy (choć już wydajność dyskowa nie jest tak oczywista). Ale już informacje dotyczące wysyłanych danych, to luksus.
AWS ma dość skomplikowany model wg którego wylicza koszt transferu danych. Poniższy graf pokazuje koszt przesyłu danych w różnych relacjach (oryginał dostępny tutaj) – co prawda ostatnia aktualizacja była w 2017 roku, jednak mimo to możemy się zorientować, które transfery kosztują i które kosztują mniej lub więcej niż inne.
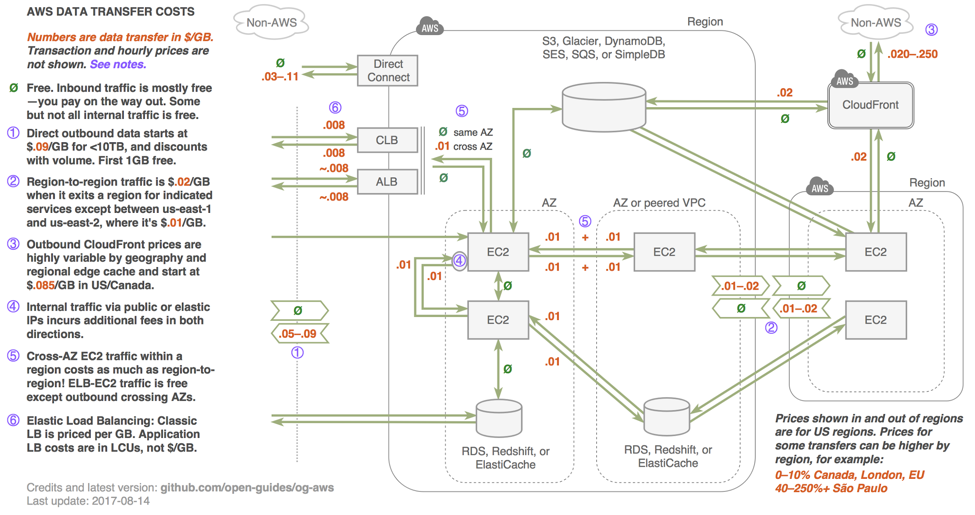
Przykładowo, ruch pomiędzy AZtami w AWS kosztuje. Ruch wychodzący w Internet również, ale już koszt tego ruchu zależy od tego, przez co go wysyłamy – np. przez Cloudfront (CND) wyślemy taniej, niż bezpośrednio z Instancji. Nie zawsze można wszystkie zasoby umieścić w jednym AZ lub jednym regionie, i konia z rzędem temu, kto wie ile danych przesyłanych jest między jego serwerami. Nawet mając dziś serwer w DMZ, który serwuje ruch dla użytkowników w Internecie, trudno jest oszacować na serwerze, ile danych widocznych np. w statystykach interfejsu sieciowego to dane wysyłane do użytkowników, a ile to dane do systemu monitoringu, backupu lub innych serwerów wewnętrznych. Możemy estymować, lub próbować zczytać to z urządzeń na granicy naszej sieci, o ile to potrafią.
Jeżeli poruszamy się w niewielkich wartościach, pojedynczych dziesiątkach GB miesięcznie – nie ma to większego znaczenia. Gorzej, jeżeli te wartości są dużo większe.
Niektóre usługi mają mniej oczywisty model wyceny. W AWS Lambda (serverless compute) płaci się za ilość wywołań funkcji, czas ich wykonania oraz ilość przydzielonej funkcji pamięci.
Jeżeli mamy doświadczenie – jesteśmy w stanie to wyestymować. Jeżeli nie – musimy coś założyć.
Chmura ma jeszcze jeden benefit względem on-premises. Jeżeli wyceniając mieliśmy złe dane wejściowe, założenia się zmieniły, koszty poszybowały w górę, to mamy kilka rozwiązań, których nie mamy w tradycyjnym datacenter:
- po pierwsze – możemy rzecz zignorować i pogodzić się z większym kosztem, jeżeli nadal ma to sens finansowy (lub inny, który jest ważniejszy) – to akurat możemy zrobić zawsze
- po drugie – możemy zrezygnować. Po prostu skasować wszystko i zapomnieć. Od tego momentu przestajemy płacić
- po trzecie wreszcie – możemy zrobić to, co w praktyce powinno być ciągłym procesem, czyli
Optymalizacja kosztów
Koszty w IT zawsze były ważne lub (niestety) najważniejsze. W końcu IT ma służyć biznesowi, dostarczać wartość, a nie być fajną zabawką. Optymalizacja kosztów w tradycyjnych DC wiązała się z inwestycjami, wymianą sprzętu, ew. zmniejszeniem parametrów jednych serwerów na rzecz innych – czyli wprost – dopychanie kolanem potrzeb do naszych możliwości.
W chmurze jest inaczej – łatwiej, ale i trudniej. Łatwiej, bo zasoby są wirtualnie nieskończone. Potrzebujesz więcej? Nie ma sprawy.
Trudniej z tego samego powodu – wirtualnie nieskończonych zasobów. Łatwo się rozleniwić i nie optymalizować bo przecież nie trzeba, nic się nie kończy. Potrzebna jest samodyscyplina, a pomaga w tym przejrzystość kosztów – wiemy dokładnie co ile kosztuje.
W związku z tym, że optymalizować można na wielu płaszczyznach, parametrów wpływających na cenę mamy bardzo dużo, to iterować możemy w nieskończoność – analogicznie gdy pracujemy nad wydajnością aplikacji – możemy to robić bez przerwy. Tylko po pewnym czasie ilość włożonej pracy nie procentuje już tak bardzo. Trzeba znaleźć złoty środek, wiedzieć kiedy skończyć. Skąd wiedzieć? Doświadczenie i wiedza…
Propozycje ograniczenia kosztów migrowanej aplikacji dostępne są w pełnej wersji artykułu (do pobrania).
To tylko wierzchołek góry lodowej, dostępnych sposób optymalizacji jest sporo (część wymieniona na stronach AWS). Żeby jednak wiedzieć, co opłaca się optymalizować, trzeba wiedzieć, co ile kosztuje oraz kiedy z kosztami przesadzamy. A do tego potrzebne są odpowiednie
Narzędzia
Każdy dostawca chmury udostępnia swoje narzędzia, więc w tej części skupię się na jednym – AWS. Do samej wyceny AWS dostarcza Simple monthly calculator. Trochę toporne, ale niezłe narzędzie, nie wspiera jednak wszystkich usług AWS, a aby zrozumieć co oznaczają ustawiane parametry, musimy często sięgać do poszczególnych cenników i dokumentacji usługi.
Szersze omówienie narzędzi i usług dostępne jest w pełnej wersji artykułu (do pobrania).
Podział kosztów wewnątrz organizacji
W tradycyjnej serwerowni było (pozornie) prosto. Kupujesz serwery, macierze, urządzenia sieciowe (ethernet, FC), system backupu, security, i… no właśnie. Podział tych kosztów na aplikacje wcale nie jest już taki prosty. Przydział dysków do serwerów jest dynamiczny, podział kosztów urządzeń sieciowych czy security wymaga mniejszej lub większej kreatywności.
Często w momencie, kiedy kończą się jakieś zasoby (np. przestrzeń macierzowa, backup) ktoś musi za to zapłacić, trzeba na to czekać, koszty całości się zmieniają a więc i koszt aplikacji się zmienia, wewnętrzne rozliczenia często nie nadążają, przez co stosuje się uproszczenia, a w efekcie klienci wewnętrzni płacą nie do końca za to, czego używają – często płacą także za innych.
W chmurze publicznej podział kosztów osiąga się poprzez nadane zasobom tagi – dzięki temu wiemy dokładnie, co ile kosztuje. Nadal koszty wspólne i zasoby, których nie da się otagować trzeba jakoś podzielić, ale większość zasobów ma dokładnie powiązany ze sobą koszt, także powiązany (np. koszt ruchu, który generują). Strategia tagowania to osobny temat, każdy dostawca dostarcza konkretne zalecenia. Otagujmy więc wszystkie nasze zasoby tak, aby móc zidentyfikować płatnika, upewnijmy się, że tagi pojawią się na otrzymanym rachunku szczegółowym, stwórzmy mechanizm który wymusi odpowiednie tagowanie.
Na tym etapie wiemy już prawie wszystko. A jednak nadal możemy trafić na niuanse, które nas zaskoczą. Listę takich przykładów znajdziemy w pełnej wersji artykułu.
Podsumowanie
Jak widać, odpowiednia wycena aplikacji w chmurze jest wypadkową wielu czynników. Nie wystarczy uruchomić kalkulatora, dodać dwa do dwóch i wyjdzie koszt. Ale czy inaczej jest w onpremie? Bez doświadczenia również nie da się poprawnie policzyć kosztu aplikacji mając wymagania typu “4 CPU, 8GB RAM, 100GB HDD – jakiś linuks z jboss’em”.
Tak więc wiedza jest kluczowa. Jeżeli jej nie masz – zdobądź ją. Jeżeli nie chcesz się uczyć na błędach – zapłać komuś, kto się na tym zna, a przy okazji tą wiedzę zdobędziesz.
Architektura aplikacji musi być przemyślana pod kątem chmury, najlepiej (najtaniej) jeżeli będzie wykorzystywała natywne rozwiązania chmurowe – czyli nie monolityczne aplikacje na instancjach, a raczej serverless, skalowalność, przetrzymywanie danych na rozwiązaniach optymalizowanych przez dostawców chmury, nie “serwerach”.
To, co wyliczymy, zawsze będzie tak dokładne jak dane wejściowe, które posiadamy. Im więcej założeń zrobimy, tym mniej dokładna będzie wycena. Ale znowu – nie różni się to niczym od klasycznego Datacenter. To, co odróżnia chmurę od DC to fakt, że łatwo coś zmienić, łatwo się wycofać jeżeli jednak koszt nie będzie dla nas akceptowalny. Spróbujcie oddać sprzedawcy serwery i macierze które kupiliście dwa miesiące temu, bo jednak wasze aplikacje nie działają na nich tak wydajnie, jak w folderze reklamowym było napisane…
Licząc koszty, mamy szeroki wachlarz narzędzi, tak natywnych, udostępnianych przez dostawców chmury, jak i cała gama zewnętrznych narzędzi. Pamiętajmy – koszty wyliczone lub tuż po wdrożeniu to pierwsza iteracja. Ciągła optymalizacja i świadomość kosztowa powinna być wpisana w naszą kulturę pracy. To także nie różni się specjalnie od on-premises, tylko tutaj optymalizacje możemy wprowadzać na bieżąco zmieniając szybko cały stack technologiczny, i mamy do tego motywację, bo mamy dokładnie zidentyfikowanego płatnika dzięki odpowiedniemu tagowaniu zasobów.
Na koniec zataczamy koło, wracając do wiedzy i doświadczenia. Może się zdarzyć, że natkniemy się na jakieś kosztowe niespodzianki i założenia (znowu założenia) które sprecyzowaliśmy, nie spotkały się z rzeczywistością, przez co koszty nie spotkały się z naszym budżetem. Jak tego uniknąć? Weryfikując koszty na bieżąco, a nie na koniec projektu. Zawsze możemy coś zmienić, zoptymalizować czy po prostu skasować.
A jeżeli z wyliczeń wychodzi, że chmura się nie opłaca – tak może być. Chmura to nie odpowiedź na wszystkie możliwe potrzeby i są scenariusze, kiedy nie będzie optymalna kosztowo. Choć nadal, z całościowego punktu widzenia, może być najlepszym wyjściem, z uwagi na inne benefity jak bezpieczeństwo, skalowalność, mniejsze nakłady na utrzymanie – wszystko zależy od konkretnych potrzeb.
Jeżeli masz wątpliwości – zapraszam do kontaktu.








{kind=link}