
Dla wielu osób, które miały możliwość pracować z Elasticsearch, okazał się on wydajną, nierelacyjną bazą danych, zorientowaną na wyszukiwanie pełnotekstowe w dużych, rozproszonych zbiorach dokumentów. Jednocześnie oferuje on również szereg mechanizmów oraz rozwiązań, które mają bezpośredni wpływ na otrzymywane przez nas wyniki. Oto pięć z nich – nie są powszechnie znane, a mogą idealnie odpowiadać potrzebom i wyzwaniom biznesowym.
1. Wyszukiwanie odwrotne, czyli Percolator
Wyobraźmy sobie, że w indeksie Elasticsearch przechowujemy oferty sprzedaży mieszkań. Oprócz standardowych pól (typu opis czy lokalizacja) każda oferta zawiera szereg mniejszych atrybutów, np. informacje o liczbie sypialni lub o tym, czy w mieszkaniu jest lodówka albo gaz. Użytkownik, który szuka mieszkania może zdefiniować konkretne wymagania i zapisać się na listę subskrypcyjną, dzięki czemu otrzyma powiadomienie za każdym razem, gdy nowe mieszkanie pasujące do jego kryteriów pojawi się w serwisie. W jaki sposób pobrać listę osób, które są zainteresowane dodawaną ofertą? Tutaj z pomocą przychodzi wyszukiwanie odwrotne i Percolator.
Model wyszukiwania Percolatora jest odwrotny do tradycyjnego. Nie wysyłamy żądania z zestawem filtrów i warunków, które są nakładane na całą kolekcję dokumentów w celu otrzymania pasujących wyników. Zamiast tego wysyłamy dokument i w odpowiedzi otrzymujemy identyfikatory pasujących zapytań. Oczywiście, takie zestawy zapytań muszą być wcześniej zdefiniowane (np. podczas zapisywania użytkownika do listy subskrypcyjnej).
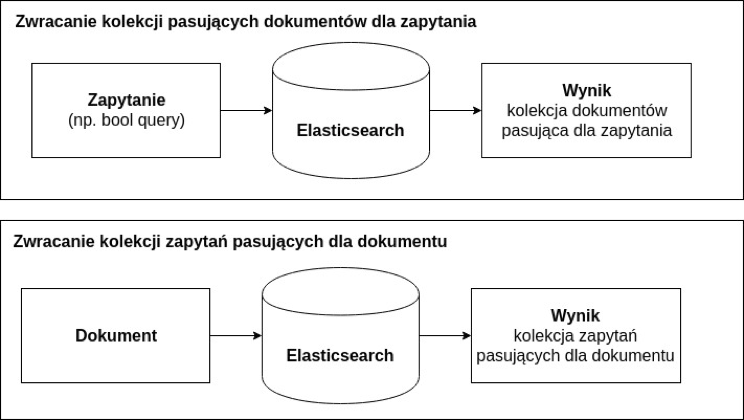
Rys. Wyszukiwanie i odwrócone wyszukiwanie w Elasticsearch.
2. Platforma wyszukiwania w czasie “prawie rzeczywistym”
Ze względu na swoją rozproszoną architekturę (wiele węzłów, shardów i replik), Elasticsearch oferuje wyszukiwanie w czasie “prawie rzeczywistym” (ang. Near Realtime Search). Może to być zaskakujące, zwłaszcza przy pierwszym kontakcie.
W praktyce oznacza to, że dokumenty dodawane do indeksu nie są natychmiast dostępne do odczytu. Takie zachowanie podyktowane jest niezbędnym kompromisem pomiędzy spójnością danych, a szybkością ich wyszukiwania, ponieważ ciągłe utrwalanie danych na dysku jest kosztowne i może powodować bardzo duże problemy wydajnościowe. Aby uniknąć takiej sytuacji, silnik Elasticsearch zapisuje wszystkie nowe dokumenty w pamięci podręcznej. Co sekundę bufor ten jest opróżniany i tworzony jest nowy segment danych wraz z logiem transakcji (ang. translog), możliwy do przeszukiwania przez klienta. Proces ten nazywany jest odświeżeniem indeksu. Log transakcji zawiera wszystkie operacje dodania, usunięcia czy aktualizacji dokumentów i ma swój limit wielkości, po przekroczeniu którego dane są fizycznie zapisywane na dysku.
Istnieje wiele zastosowań Elasticsearch, w których dane nie są przeszukiwane od razu po dodaniu, a więc nie ma potrzeby ciągłego zapisywania ich na dysku. Dzięki temu nie ograniczamy niepotrzebnie wydajności całej maszyny.
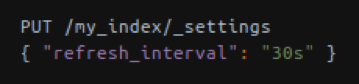
Rys. Zmiana czasu, który odpowiada za odświeżanie indeksu.
Podczas dodawania dokumentu do indeksu lub jego aktualizowania można określić, czy dokument taki powinien być widoczny od razu po wykonaniu żądania. Odpowiada za to dodatkowy argument ?refresh. Dzięki niemu można poczekać, aż indeksy się odświeżą (co wpływa na czas realizacji samego zapytania) lub wymusić odświeżenie od razu po modyfikacji, jednak to zmniejszy wydajność samego klastra.
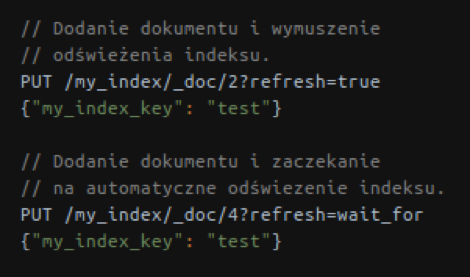
Rys. Polityki odświeżania indeksu.
3. Analizator języka polskiego – Stempel
Główną cechą silnika Elasticsearch jest możliwość wyszukiwania pełnotekstowego za pomocą procesu analizowania składni. Analiza odbywa się zarówno na poziomie zapisywania dokumentu w indeksie, jak i podczas wysyłania żądania wyszukującego i nie jest tak skomplikowana jak może się na początku wydawać. Składa się z przygotowania przesłanego ciągu znaków i zamiany go na tokeny (ang. tokenizer). Na każdym tokenie przeprowadzane są operacje filtrowania.
O ile natywne mechanizmy bardzo dobrze radzą sobie z językiem angielskim, o tyle polskie słowa nie są wspierane. Z pomocą przychodzi jednak rozszerzenie Stempel, które oferuje zarówno polski analizator, jak i stemming. Bez wchodzenia w zbędne szczegóły, w praktyce oznacza to sprowadzanie każdego analizowanego tokenu do jego rdzenia (np. dla wyrazów: klucznik, kluczowy, klucze rdzeniem jest wyraz klucz).
Przy użyciu odpowiedniej konfiguracji, to znaczy zdefiniowaniu mapowania dla dokumentu i analizatorów dla pól, jesteśmy w stanie osiągnąć bardzo różne wyniki (w zależności od potrzeb). Do przykładowej kwerendy “darmowy basen we Wrocławiu” mogą zostać dopasowane nagłówki takie jak “Wrocław: za mało darmowych basenów” czy “Mapa darmowych miejsc we Wrocławiu”, oczywiście oznaczonych odpowiednim scoringiem (współczynnikiem dopasowania zapytania do zwracanego wyniku).
4. Skala ma znaczenie
Zaczynając pracę z Elasticsearchem łatwo zbagatelizować własne wybory i decyzje przy projektowaniu klastra czy struktury przechowywanych dokumentów. Otwieramy jeden z tutoriali i wykonujemy zapisane w nim kroki jeden po drugim, w niewielkim tylko stopniu dostosowując je do swoich potrzeb. Nie wynika to ze złej woli czy ignorancji – najczęściej to naturalny proces poznawania i oswajania się z nowym środowiskiem i zazwyczaj nie ma negatywnych skutków (o ile nie spoczniemy na laurach w przekonaniu, że skoro działa, to na pewno umiemy już projektować wydajne i niezawodne rozwiązania).
W przypadku Elasticsearch czynnikiem, który ma ogromny wpływ na działanie całego klastra jest skala przechowywanych w nim danych. Wielce prawdopodobne, że aplikacja będzie działała stabilnie przy klastrze przechowującym kilkanaście GB danych, ale po przekroczeniu pewnej granicy (np. kilku TB) pojawią się problemy, które na tym etapie zazwyczaj będą kosztowne do wyeliminowania.
Istnieje wiele artykułów i metryk przedstawiających bardzo dużą wydajność rozwiązań opartych o Elasticsearch, jednak zdecydowana większość z nich dotyczy zbiorów o dużej retencji (kilka miesięcy czy lat). Sztandarowym przykładem są tutaj logi, które przechowywane są przez ustalony okres. Indeksy zawierające starsze dane, takie, które z biznesowego czy technicznego punktu widzenia nie są już istotne, zostają zamknięte i nie biorą udziału w przeszukiwaniu klastra.
Często pojawiającym się zagadnieniem w społeczności Elasticsearch jest kwestia doboru liczby shardów i replik do liczby przechowywanych danych. Nie ma tutaj uniwersalnego rozwiązania. Wpływ na tę konfigurację ma charakter przyrostu danych (czy jest w funkcji czasu, czy może indeksy powinny być alfabetyczne).
Należy też pamiętać, że każdy shard to tak naprawdę jeden indeks Lucene, który ma swoje wewnętrzne ograniczenie ilości przechowywanych w nim dokumentów, wynoszące około 2.1 mld rekordów.
5. Architektura hot-warm
Pozostając przy tematyce skali w Elasticsearch warto wspomnieć o architekturze hot-warm. Idea jest bardzo prosta – wychodząc z założenia, że klaster składa się z danych przyrostowych w czasie (np. archiwum rozmów komunikatora, logi aplikacji, analiza zachowania użytkowników), można wysunąć założenie, że klient (aplikacja czy osoba, która wykorzystuje zebrane dane) nie potrzebuje za każdym razem danych historycznych, a więc takich, które zostały zapisane np. rok temu. Bardzo często informacje z ostatnich kilku miesięcy czy lat są w zupełności wystarczające do działania aplikacji. Dobrym przykładem jest tutaj komunikator rozmów i archiwum wiadomości. Zazwyczaj użytkownicy wracają do wiadomości sprzed kilku tygodni, miesięcy, najwyżej lat. Sporadyczne żądania dotyczą przeszukiwania archiwum aż do pierwszej wiadomości.
W takim przypadku, aby zminimalizować koszty całego klastra, warto zastanowić się nad architekturą, która na szybkich i mocnych pod względem obliczeniowym maszynach przechowuje ostatnie i najczęściej odpytywane indeksy, podczas gdy dane archiwalne przetrzymywane są na sprzęcie słabszym (ale tańszym w utrzymani) i nadal pozostają dostępne do przeszukiwania, chociaż z mniejszą wydajnością. Co więcej, takie przenoszenie danych z węzłów gorących (ang. hot) do ciepłych (ang. warm) może być w pełni zautomatyzowane za pomocą modułu o nazwie Curator, który zadba za nas o odpowiednie łączenie indeksów i obsługę całego procesu.
Takie podejście do zagadnienia pozwala na skalowanie dużych zbiorów danych przechowywanych w klastrze Elasticsearch wraz z rozsądnym zarządzaniem budżetem.
Elasticsearch stanowi bardzo dobry silnik dla wyszukiwania pełnotekstowego, który z powodzeniem radzi sobie z ciągłym i dużym przyrostem danych, nie tracąc przy tym na wydajności wyszukiwania. Znając i rozumiejąc mechanizmy znajdujące się “pod maską” jesteśmy w stanie dopasować oferowane możliwości do swoich potrzeb. To kolejny dowód na to, że niekonwencjonalne wykorzystanie znanych narzędzi prowadzi do efektów, które przerastają oczekiwania użytkowników. Warto z tego korzystać.







