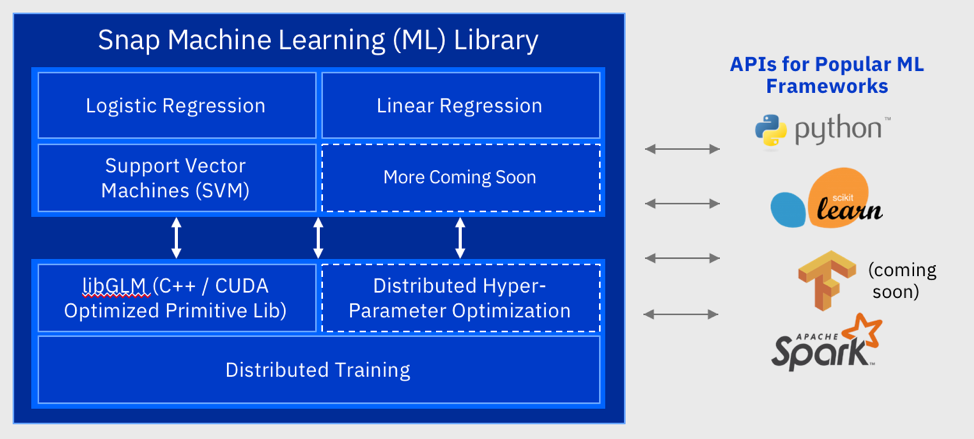
IBM ogłosił, że zastosowanie nowego framework’u SNAP ML i serwerów Powr9 GPU do zbioru danych referencyjnych Criteo dało wynik 46 razy lepszy niż dotychczasowy benchmark, czyli Google TensorFlow. Co ważne przyspieszono najczęściej stosowane algorytmy, jak regresja logistyczna, a to może mieć bardzo szerokie implikacje biznesowe.
-
Wg badań przeprowadzonych przez Kaggle w 2017 roku wśród 16 tys. specjalistów zajmujących się badaniem danych (Data Science) regresja logistyczna była najczęściej stosowanym przez nich narzędziem analizy (ponad 60%).
-
Znaczne przyspieszenie działania tej rodziny metod ma zatem bezpośrednie implikacje dla zastosowań w praktyce biznesowej.
Szeroko znana jest zależność algorytmów głębokiego uczenia (Deep Learning) od GPU i przyspieszenie jakie dzięki ich zastosowaniu uzyskują. Dotychczas jednak zagadnienie przyspieszenia tradycyjnych metod takich jak regresja logistyczna czy SVM (Support Vector Machine) – maszyna wektorów wspierających, stanowiło wyzwanie oczekujące na swój czas. Zespół laboratorium badawczego IBM w Zurichu zdołał osiągnąć wynik 46 razy lepszy od poprzedniego benchmarku jaki był wynik Google TensorFlow. Zespół wziął na warsztat klasyfikator regresji logistycznej i przeprowadził trening w kierunku przewidywania klikalności reklam przy użyciu zbioru danych Criteo Labs (skala TB), który składa się z danych charakteryzujących dzienne kliknięcia reklam online i zawierających 4,2 miliarda przykładów treningowych określających czy użytkownik kliknął reklamę i przy jakich warunkach.
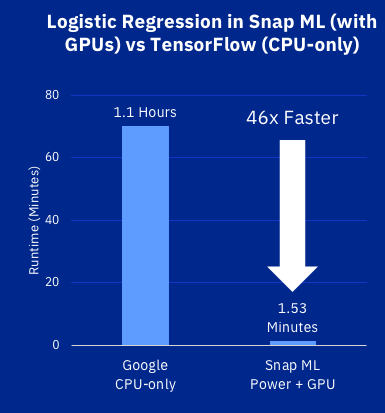
Wcześniejszy wynik Google uzyskany w oparciu o ten sam zestaw danych, przy wykorzystaniu serwerów chmurowych TensorFlow i jednostek CPU, wynosił 70 minut. IBM uzyskał analogiczną dokładność modelu w czasie zaledwie 91,5 sekundy. Zespół dokonał tego z wykorzystaniem czterech serwerów AC922, wyposażonych w dwa procesory Power9 i cztery procesory graficzne NVIDIA V100.
Choć sceptycy wskazują, że przyspieszenie uzyskano głównie dzięki zastosowaniu GPU, nie jest to cała prawda. Zastosowanie GPU nie implikuje wprost przyspieszenia obliczeń dla dowolnego modelu. W omawianym przypadku badacze Google wskazywali, że zrezygnowali z zastosowania GPU ze względu na niewielki spodziewany uzysk czasowy. Dzieje się tak dlatego, że największy koszt czasowy powodują operacje na pamięci przechowującej duży zbiór danych. To właśnie ten aspekt zaadresowali badacze IBM w pierwszej kolejności optymalizując lokalizację danych w pamięci GPU i podział zbioru danych na mniejsze fragmenty.
Implikacje biznesowe
Według IBM, zdolność do radzenia sobie ze zbiorami danych w efektywny czasowo sposób sprawia, że SNAP ML jest dobrym kandydatem do zastosowań w przetwarzaniu danych w czasie rzeczywistym lub w czasie zbliżonym do rzeczywistego, gdzie model musi zostać wytrenowany na danych strumieniowych on-line. Framework powinien również być przydatny w zagadnieniu uczenia zespołowego, gdzie kilka klasyfikatorów wypracowuje wspólne rozwiązanie (konsensus) danego problemu.
Przekłada się to też jednoznacznie na koszty budowania modeli w chmurze. Modele regresji liniowej są najczęściej stosowanymi metodami do analizy danych w praktyce biznesowej. 46-krotne skrócenie czasu budowy modelu oznacza możliwość uruchomienia 45 modeli więcej w chmurze przy tym samym budżecie, albo redukcję kosztu budowy modelu – np. z 45 USD do 1 USD.
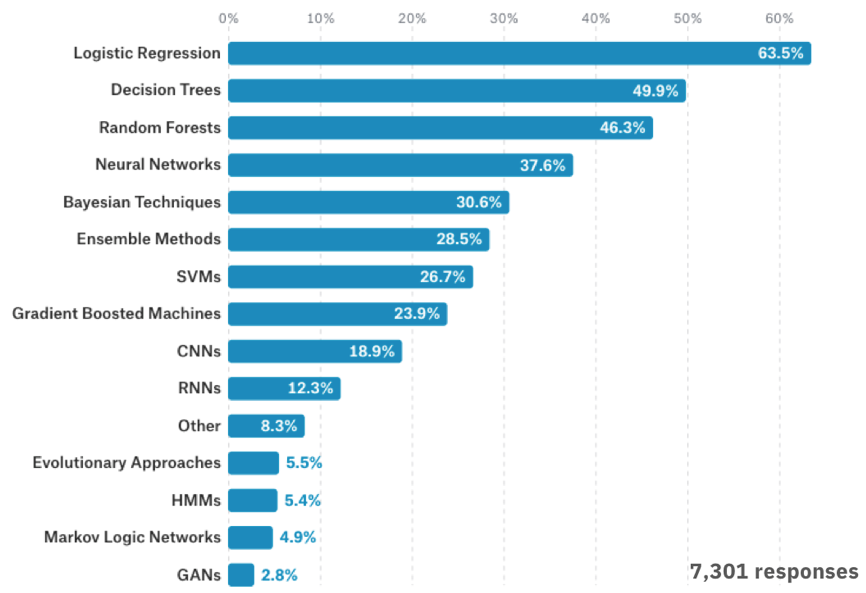
Najczęściej stosowane algorytmy uczenia maszynowego, Kaggle 2017 Survey.
Artykuł opublikowany przez badaczy IBM w Zurichu: Snap Machine Learning.